Scaling is one of the biggest challenges in web-scraping niche and there are a lot of ways to make web-scrapers scale better in efficiency, speed and reliability. However, there's one thing can be done to web-scraper code that is by far the biggest bang-per-buck improvement: using asynchronous code.
In this short article, we'll take a look at asynchronous python and how we can take advantage of it to make our scrapers over 100 times faster!
What is Asynchronous Programming?
Python supports many async code paradigms, however the current de facto standard is async/await via asyncio (or it's alternatives like trio). In this article we'll keep focus on asyncio as it's currently the most approachable async paradigm in Python.
So what is asynchronous programming?
At it's core it's essentially just pausable functions (called coroutines) which can pause when inactive and give way to active ones. This often has huge benefits in IO (input/output) bound programs that rely on waiting for some sort of external input or output.
What is an IO block?
When programs interact with external service they often need to wait for the service to respond: this waiting is called IO block. Some examples of IO blocks:
- In online apps IO block would be waiting for server to respond to requests.
- In GUI apps this would be waiting for app user to click buttons, enter text or interact with other GUI widgets.
- In video games this would be waiting for the player to perform some actions.
IO blocking is a big deal in web-scraping, since the majority of actual work the program does is communication with the web server.
For example, in synchronous python when we send a request to a server our code stops - does absolutely nothing - while waiting for the server to respond. In web-scraping this can be up to several seconds, and they add up really quickly!
Presumably, we have 100 urls to scrape that wait 1 second each - that's over a minute and a half of waiting! Could we make them wait together concurrently?
How Does Async Web Scraping Work?
In these examples we'll be using httpx http client package which supports both synchronous and asynchronous client APIs
Let's take a look at a quick example. We have 100 urls that we want to scrape, and we have this really simple synchronous scraper code:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 | |
Here we're taking advantage of https://httpbin.org delayed response endpoint /delay/<n> which will simulates slow server which takes N seconds to respond. This tool is great for testing web scraping scaling!
In this example, we schedule 100 different requests synchronously that each should take at least 1 second to execute each: 1 second delay by the server + all connection overhead our machine does = 100+ seconds.
Now let's try to run those 100 request at the same time, asynchronously by using asyncio async loop and asyncio.gather() function:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 | |
If we run this minor async modification, we'll see a colossal speed boost:
finished scraping in: 2.4 seconds
We sped up our scraper over 50 times just by converting few lines of code into asynchronous python! Let's take a look at small illustration of the performance of these two programs:
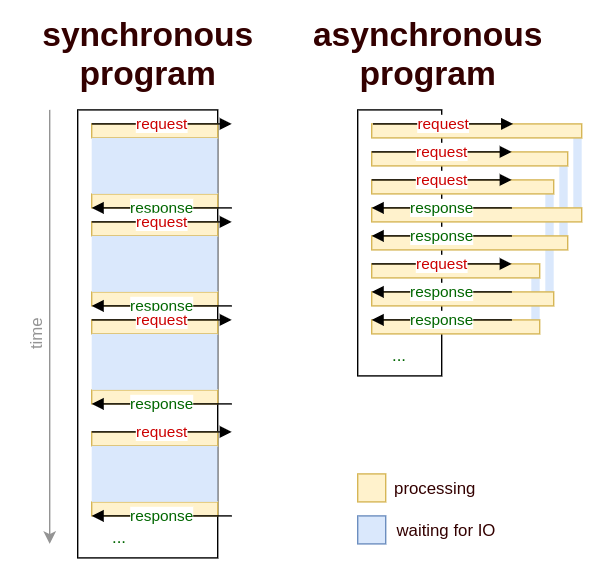
Here, we can easily visualize the difference between synchronous and asynchronous scraper programs: the IO waiting on the left is part of the program, while on the right it doesn't have to be!
Async programs essentially prevent IO waiting from blocking our programs. For waiting intensive tasks such as http connections, async essentially means concurrency and can speed up programs from dozens to thousands times over!
However, as the illustration shows, there are some negatives to async programming:
- Ensuring execution order can be difficult.
Often, request order can be very important in session or cookie bound web scraping. Keeping track of sessions and cookies is much more complicated in async environment. - Async programs are much harder to design and debug since they are inherently more complex.
- Async speed can be major pain when dealing with scraper bans which require programming of throttling logic.
Whether this overhead of complexity worth it for your web scraper entirely depends on your program. For small scripts, it might not be worth tangling up with the whole async ecosystem, which is still quite young in Python. However, for big data scrapers, async provided speed boosts of 100-1000x are vital for any reasonable data collection speeds!
We're Going Too Fast: Throttling
Using async python we can make a lot of http requests very quickly, which can become problematic. Web servers often try to protect themselves from high traffic as it's resource expensive and will often block scrapes that connect too quickly.
To avoid bans and blocks, we must either use multiple proxies or preferably throttle our connections. Let's take a look at few common ways to throttle web-scrapers.
Asyncio's Semaphore
This is built in way to throttle coroutine concurrency in python's asyncio. Semaphore is essentially a lock object with limited amount of working slots, i.e. it allows us to specify that no more than N coroutines should be executed concurrently:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 | |
Here we modified our async scraper code with one key addition of asyncio.Semaphore(10) object, which limits concurrent execution to 10 concurrent coroutines. Our original unlimited code took 2.4 to complete now we managed to slow it down 6 times with few extra lines of code!
Some important things to notice about asyncio.Semaphore:
All throttled coroutines should be use same Semaphore object. This means one throttled needs to be passed around to each individual coroutine introducing slight complexity overhead.
Semaphore is only aware of concurrency, not time. Often when web-scraping we want to limit request count to specific time frame like max 60 requests / minute. In other words, our Semaphore(10) when scraping fast servers could yield 10 requests / second however on slower ones it might be only 2 requests / second.
While Semaphore gives us an easy way to throttle ourselves, we can see it's not an ideal approach as it doesn't allow us to be as precise as some web-servers might require us to. Often web servers have strict limits like 60 requests/second - for most efficient web scraper we would like to stay around that range - let's take a look how can we accomplish this.
Leaky Bucket
Leaky Bucket is a common throttling algorithm that uses time tracking for throttling rather than just concurrency. Using the Leaky Bucket approach, we can specify how many tasks can be executed in a specific time frame, i.e. we can throttle our scraper to 10 requests/second!
A popular implementation for python's asyncio is available in aiolimiter package. Let's take a quick look, how can we use it in our web-scraper:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 | |
Here we merely replaced our Semaphore from previous code with aiolimiter.AsyncLimiter which allows us to be much more precise: we completed our 100 scrape tasks in 10.4 seconds which matches our limit of 10req/second almost exactly!
Leaky bucket is a great throttling approach as it allows us to scrape in predictable and controlled speeds. That being said predictability is not a great web scraper feature when it comes to blocking and banning - scraper can be identified quite easily if it shows a consistent pattern of connections.
So which throttling pattern to use entirely depends on scraped targets, but Leaky Bucket is often the best approach!
How Much To Throttle?
Finally with throttling figured out, we need to decide on the number? Unfortunately, there are no standard accepted practices other than it's respectful to keep connection number lower to not cause issues to web servers.
Keeping in the 10-30 requests/second range (depending on page and website size) is widely considered to be a respectful scraping rate - so that's a good starting point. Other than that it's a good idea to grab some proxies and experiment!
Summary, Alternatives and Further Reading
In this introductory article, we've taken a look how we can use asynchronous python to speed up our web-scrapers to the point where we had to figure out how to throttle ourselves! For throttling, we've discovered Semaphore and Leaky Bucket approaches and how can we apply them in web-scraping.
Asynchronous programming can often be difficult, complex and even ugly. However, when it comes to such IO heavy tasks like web connections in web-scraping it is often unavoidable, so better get comfortable with it!
As for further reading and alternatives?
Asynchronous programming is not a new concept by any means, but it's still evolving in many different directions. In this article we focused on Python's async/await approach, however there are other paradigms that are also used in web-scraping.
One of the biggest web-scraping frameworks Scrapy is using Twisted callback based async engine which allows running functions in the background and call result function once they complete. Callbacks and Futures are also often used in Javascript and can be used in Python's asyncio as well!
Other than that, Celery task engine is also often used to execute scraping tasks concurrently.
Gevent is yet another popular asynchronous library that integrates well with web-scraping ecosystem.
In the future of this blog we'll cover more examples of these alternative approaches, however do not underestimate python's asyncio - as we've seen in this article it's extremely fast, surprisingly accessible and once understood can be an absolute pleasure to work with!
So stick around for more articles and if you have any questions, come join us on #web-scraping on matrix, check out #web-scraping on stackoverflow or leave a comment below!
As always, you can hire me for web-scraping consultation over at hire page and happy scraping!