
Unfortunately for web-scrapers modern websites are much more than html files strung together and served over http protocol. Often websites are complex structures of multiple executions layers and file formats that are designed specifically for one of the most complex programs in the world - web browsers.
So how do we scrape complex websites without using web-browsers? We can reverse engineer websites behavior and replicate it in our code!
In this article will cover a short introduction how to use web browser's developer tools to reverse engineer website's behavior. We'll be using https://food.com as our example and cover some useful tips and tricks.
In this article we'll be using Chrome web browser. That being said Chrome based browsers (like Brave, Electron, Qutebrowser etc.) use the same tools and should function the same. However Firefox and it's browser family use slightly different tools
Browser Developer Tools
Fortunately, modern web browsers come with great debugging tools referred to as "Developer Tools". For this article we'll take a look at Chrome web browser. If you fire up Chrome browser and click F12 (or right click anywhere on the page and select inspect) developer tool window will open up:

As you can see, there's a lot going on here. Let's quickly go through these tools and see what they can do to us when it comes to web-scraping. First, let's take a look at the available tool tabs:
Elements - this tab allows to visually explore, search and investigate the html page structure. For

Console - this tab functions like a real time shell or a repl. You can type javascript expressions here and they will be evaluated against the current page.

Application - contains various application data: from cookies to database entries. This is rarely used by websites but often used by various web-apps. For web-scraping this tab is not referred to commonly.

Network - probably the most interesting tab: it shows all of network requests made by the browser. Most useful web-scraping tool of the bunch!

As you can see it's a huge suite of web tools! However the most interesting tool when it comes to reverse-engineering for web-scraping purposes has to be the Network tab. Let's take a look how we can configure it for optimal experience and some examples of how to use it.
Network Inspector
This browser tool shows us all the requests our browser is making when we're browsing the web.
First, let's take a look at the window itself. Specifically how to read it in the context of reverse-engineering for web-scraping:

There's a lot going here but don't get overwhelmed just yet. We only need to focus on these parts:
- Contains all requests your browser made to the website. You can click on each individual one to further inspect it (We'll dig into this more below).
- Option flags that disable cache and stop data clearing on page load (These are very useful for reverse engineering)
- Contains powerful filtering system. For the most part we'll be spending most of our time in either
Docfilter which shows allhtmldocument requestsXHRfilter which shows all data requests such asjson.
- Clear button
⍉which clears current requests for easier tracking of what's going on.
Further, we can take a look at individual request itself and which parts are most useful for reverse-enginering. If you click on one of the requests you should see something like:
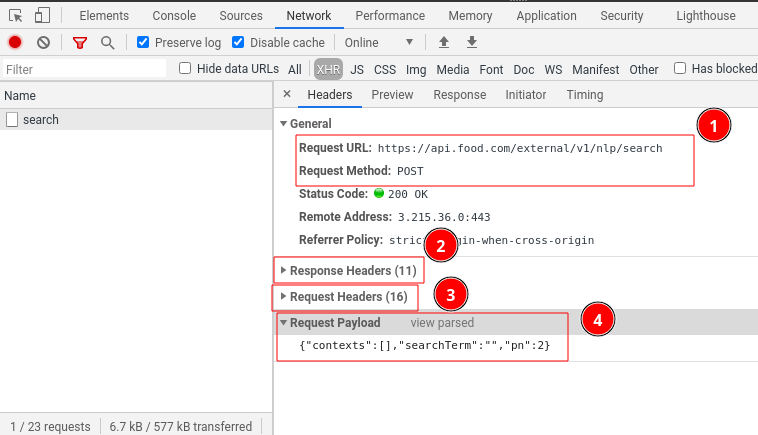
In this window we see several important information fields:
- Basic request details
Most important details here are URL and request method. -
Response headers
Rarely interesting but can contain important meta data about response browser received from the website, such as:Set-Cookieheader
contains cookies website requests the browser to saveContent-Typeheader
contains the type of response. Most common values are eithertext/htmlfor html documents orapplication/jsonfor json data.X-prefixed headers
these are non-standard headers that are often used for website functionality, tracking or anti-bot protection.
If you'd like to learn more about http headers see MDN's http header documentation
-
Request headers
Headers browser sent with this request. Often we want to replicate most of these headers in our web-scraper as closely as possible. Most common and vital ones being:Content-TypeandAccept-prefixed headers
these are instructions for what sort of content is expected. Often http client libraries (likerequestsfor python) fill them in automatically, thus it's important to keep an eye on these as sometimes they might be generated differently from the our browser.User-Agent
identifies who is making the request. This is really important field for preventing basic bot blocking. Usually we want to set this to one of popular browsers on popular OS systems like Chrome on Windows.
-
Request Payload
This mostly used when dealing withPOSTtype requests. It shows what data browser sends to the website. Usually it's some sort of request parameters in json format.
As you can see, Network Inspector is a surprisingly powerful and extremely useful reverse engineering tool that shows us what connections our browser is performing in a very detailed manner!
Now that we're somewhat familiar with it, let's take a look at common usage tips and several iconic web-scraping problems that can be solved by using this tool.
Tip: Replicating Requests in Python
There's an easy way to replicate requests seen in the Network Inspector in your python code.
If you right-click on a request, you can see that the Network Inspector allows exporting it in several formats:
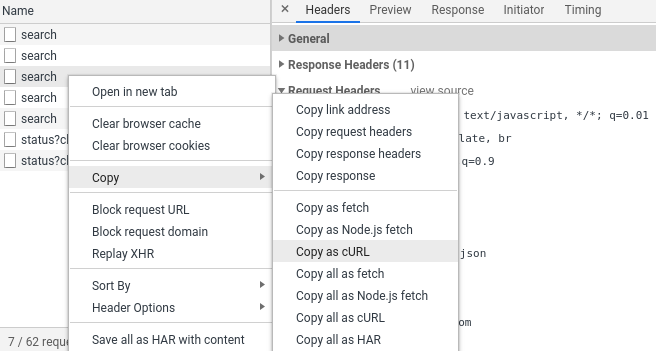
While there's no "copy as python" button there is "copy to curl" button which produces a curl command line tool command with all of the request details attached. Something like:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 | |
There are several tools that can convert this string into code!
- https://curl.trillworks.com/ - can convert it to multiple languages, python
requestsbeing one of them. - https://github.com/spulec/uncurl - is a library that can convert it to python objects or full python
requestscode.
Using either of these converter tools we can quickly prototype our web-scraper while reverse engineering our target.
Common Case: Dynamic Javascript Pagination
One of the most common encountered web-scraping issues is dynamic content generation powered by javascript. Modern websites often use javascript to generate web page content on the fly rather than redirecting users to a new page.
Most commonly this is observed in item pagination - instead of sending the user to page 2 directly its data is requested in the background and inject it back to document's body using javascript.
This is often referred to as never-ending or dynamic pagination.
Common identifiers of dynamic pagination:
- Instead of pages users just need to scroll down and more results are loaded
- Clicking page doesn't reload the current page just the pagination part.
- Pagination doesn't work with javascript disabled.
Scraping Recipes from Food.com
For example let's take a look at how https://food.com does it in their recipe search:
As you can see, the content of this website loads dynamically every time the user scrolls the page.
This technique is especially common in Single Page Applications (SPA) - where the whole idea is that the user never needs to switch locations and content is dynamically replaced
For more information on Single Page Applications see MDN's documentation on SPA
Since our web-scraper is not a browser (unless we use browser emulation) it doesn't execute javascript. Meaning to access this dynamic content we must reverse engineer the behavior so we can replicate it in our code.
Let's fire up devtools' Network Inspector and see what food.com does when we scroll down:
We can see that when we continue scrolling search requests are being made. That's actually data for the whole page of recipes which when received is being injected into the html page by javascript.
Let's take a look at these requests and how we can replicate them in our web-scraper:
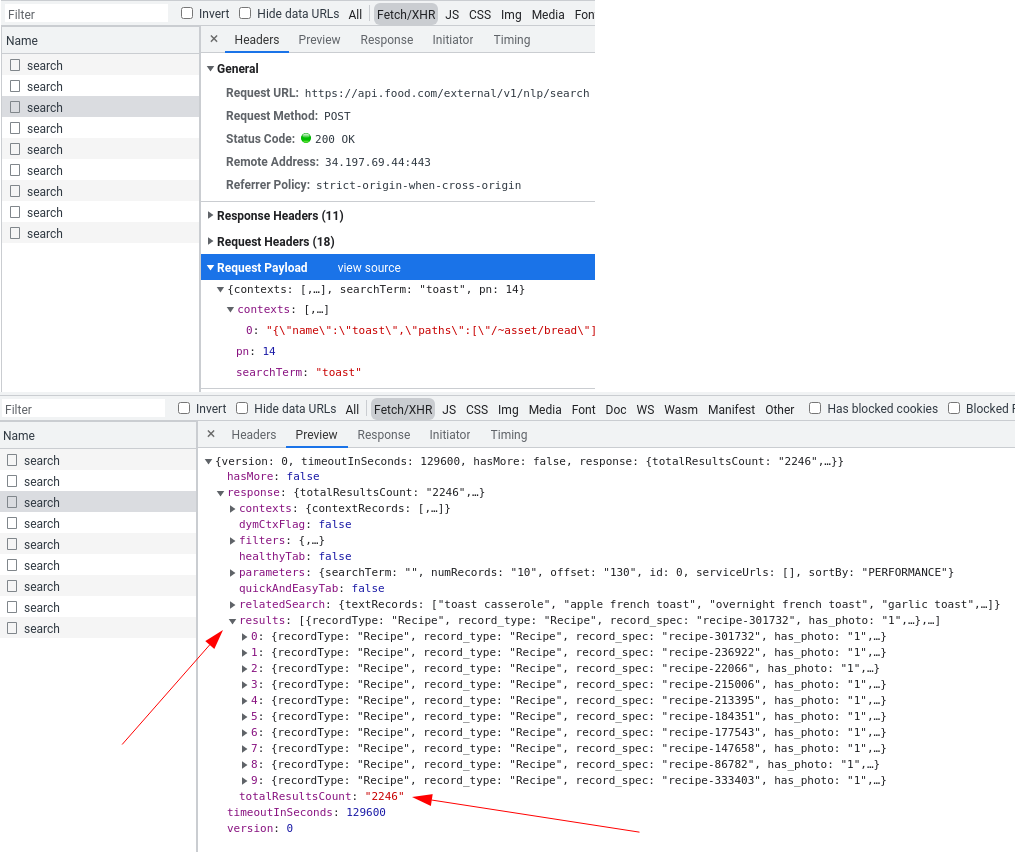
Here we can see that the request being made is a POST type request to https://api.food.com/external/v1/nlp/search and it's sending some JSON data. In return it received json document with 10 recipes and loads of meta information - like how many pages are there in total. That's exactly what we're looking for!
Let's take a look at the document we need to send to receive this information.
Under "Request Payload" we see json document:
1 2 3 4 5 6 7 | |
Some context data seems to be sent, search term "toast" and pn integer argument which seems to be short for page number. Great, that means we can request any page for any search term!
Let's replicate this request in Python:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 | |
It works! We've successfully reverse engineering food.com's backend API for it's paging function and replicated it in this Python scraper script!
If you noticed, we skipped the contexts object in our POST body entirely. The great part about reverse engineering something is that we can adjust its functions and have clean, efficient, beautiful programs. This is great for us as our scraper programs use less resources and are easier to follow and maintain, and it's also better for our target - food.com - as we consume fewer of their resources by only the scraping specific data targets rather than loading the whole page and all the extras such as images, videos etc.
Summary And Further Reading
In this short introduction article we covered what are browser developer tools and how can we use them to understand basic workings of javascript driven websites. We've covered example case of how https://food.com is using javascript for never-ending-pagination and how can we replicate it in Python using requests package.
Reverse engineering story doesn't end here - web is becoming more complex by the day and browser's devtools only scratch the surface of what we can learn about websites. In the future we'll cover advanced reverse engineering topics such as using man-in-the-middle monitoring programs such as mitmproxy, fiddler and wireshark that allow even more detailed inspection and various quality of life tools such as request interception and scripting. These tools not only allow to reverse engineer websites but desktop and mobile applications!
So stick around for more articles and if you have any questions, come join us on #web-scraping on matrix, check out #web-scraping on stackoverflow or leave a comment below!
As always, you can hire me for web-scraping consultation over at hire page and happy scraping!