
Most web scrapers are made up of two core parts: finding products on the website and actually scraping them. The former is often referred to as "target discovery" step. For example to scrape product data of an e-commerce website we would need to find urls to each individual product and only then we can scrape their data.
Discovering targets to scrape in web scraping is often a challenging and important task. This series of blog posts tagged with #discovery-methods (also see main article) covers common target discovery approaches.
In this article we'll take a look at web crawling and how can we use it as a discovery strategy in web scraping.
What is recursive crawling and how is it used in web-scraping?
One of the most common ways to discover web scraping targets is to recursively crawl the website. This technique is usually used by broad scrapers (scrapers that scrape many different websites) and index crawlers such as Google and other search engine bots.
In short crawling is recursive scraping technique where given a start url and some crawling rules the scraper continues exploring the website by visiting all'ish of the links present on the website.
To wrap our heads around crawling concept easier lets refer to this small flow chart:
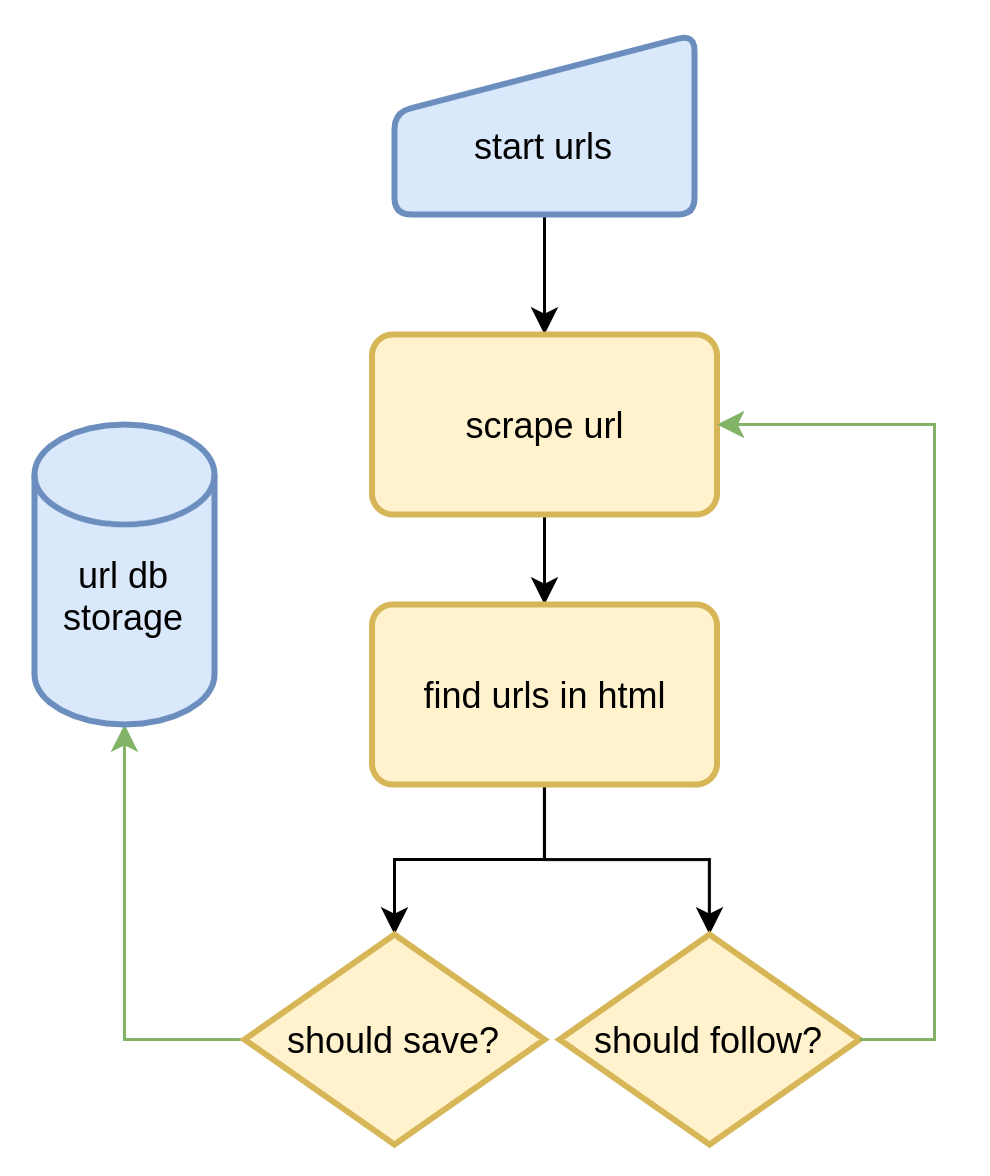
This flow chart illustrates the simplest domain-bound crawl spider flow: the crawler is given a starting point, it scrapes and parses it for urls present in the html body. Then applies matching rules to urls and determines whether to save to urls (for scraping later) or whether to follow them up to repeat the whole process.
Before using crawling as a web scraping discovery strategy it's a good practice to reflect on common pros and cons of this technique and see whether that would fit your web-scraping project:
Pros:
- Generic Algorithm: can be applied to any website with few adjustments. In other words one web scraper can be adapted to any website quite easily.
- Good Coverage: some websites (like e-commerce) are well interlinked thus crawling will have great discovery coverage.
- Easy to Develop: no reverse-engineering skills are required since we're just falling natural website structure.
Cons:
- Inefficient and Slow: since crawling is a very generic solution it comes with a lot of inefficiencies. Often extracted links might not contain any product links so lots of crawl branches end up in dead ends.
- Insufficient Coverage: some websites are not well interlinked (sometimes purposefully to prevent web scrapers). Crawlers can't discover items that are not referenced anywhere.
- Risk: since scraped link bandwidth is much bigger than other discovery approaches the scrapers IPs are more likely to be throttled or blocked.
- Struggles With Javascript Heavy Websites: since crawling is very generic and web scrapers don't execute javascript content (unless using browser emulation) some websites might be too complex for web scraper to follow.
We can see that crawling is a smart generic way to discover scrape targets however it's not without it's faults: it's slower, less accurate and might be hard to accomplish with some javascript heavy websites.
Lets take a look at example target discovery implementation that uses web crawling.
Example Use Case: hm.com
Lets take a look at a popular clothing e-commerce website: https://hm.com. We'll be using crawling approach to find all clothing products on the website.
First lets establish essential parts that make up a web crawler:
- Link extractor - a function/object that can find urls in html body.
- Defined link pattern rules to follow - a function/object that determines how to handle up extracted links.
- Duplicate filter - object that keeps track of links scraper visited.
- Limiter - since crawling visits many urls we need to limit connection rate to not overwhelm the website.
These are 4 components that make up a basic web crawler. Lets see how we can implement them for hm.com.
Crawling Rules
First lets establish our crawling rules. As per above flowchart our crawler needs to know which urls to follow up and which to save:
1 2 3 4 5 6 | |
Here we defined our crawling rules:
- We want to save all urls that contain
/productpage.in the url as all hm.com products follow this pattern - We want to follow up any url containing
.html -
Do not follow urls that are being saved.
Following saved urls can useful as product pages often contain "related products" urls which can help us increase discovery coverage. For hm.com domain this is unnecessary.
These are 3 rules that define our crawler's routine for domain hm.com. With that ready lets take a look how we can create a link extractor function that will use these rules to extract crawl targets.
Crawl Loop
Having crawling rules defined we need to create a crawl loop that uses these rules to schedule a whole crawl process.
In this example for our http processing we'll be using httpx and for html parsing parsel python packages. With these two tools we can define basic crawler skeleton:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 | |
With this skeleton, we have basic usage API for our scraper. We can define our run function:
1 2 3 4 5 6 7 8 9 10 | |
Great! Now all we have to do is fill in the interesting bits: link extraction and scrape loop.
For scrape loop all we need to do is request urls, find links in them, follow or save ones that match our rules:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 | |
Here we've defined an "endless" while loop that does exactly that: get htmls, parse them for urls where we store some of them and follow up the others. The last remaining piece is our link extraction logic.
Link Extracting
Link extraction process is the core part that makes the crawler and can get quite complex in logic. For our example domain hm.com it's relatively simple. We'll find all urls in the page by following <a> nodes:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 | |
Here we first build a tree parser object to get all those <a> node links. Then we iterate through them and filter out anything that is not an url of this website or has been visited already.
Link Extraction can get complicated very quickly as some website can contain non-html files (e.g. /document.pdf) that need to be filtered out and many other niche scenarios.
With link extraction complete, we can put together our whole crawler into once piece and see how it performs!
Putting It All Together
Now that we have all parts complete: crawl loop, link extraction, link matching and request limiting. Let's put it all together and run it:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 | |
If we run our crawler we'll notice few things: - At time of writing 13800~ results are being found which matches well with our other #discovery-methods used in this blog series. - It took a while to complete this crawl: TODO second. Since we are crawling so many pages compared to other discovery methods we crawl
Finally, we can see that we can easily reuse most of this scraper for other websites, all we need to do is change our rules! That's the big selling point of crawlers, is that they're less domain specific than individual web scrapers.
Summary and Further Reading
To summarize, web crawling is a great discovery technique that lends easily to generic/broad scraper development because the same scrape loop can be applied to many targets just with some rule adjustments. However it's less efficient - slower and riskier when it comes to blocks - than other discovery techniques like Search Bar or Sitemaps.
For more web-scraping discovery techniques, see #discovery-methods and #discovery for more discovery related subjects.
If you have any questions, come join us on #web-scraping on matrix, check out #web-scraping on stackoverflow or leave a comment below!
As always, you can hire me for web-scraping consultation over at hire page and happy scraping!
The code used in this article can be found on github.