
Most web scrapers are made up of two core parts: finding products on the website and actually scraping them. The former is often referred to as "target discovery" step. For example to scrape product data of an e-commerce website we would need to find urls to each individual product and only then we can scrape their data.
Discovering targets to scrape in web scraping is often a challenging and important task. This series of blog posts tagged with #discovery-methods (also see main article) covers common target discovery approaches.
Using various public indexers is a often viable target discovery strategy. It is mostly used as a last resort or as a supplementary technique for difficult discovery-difficult targets.
Public indexers that crawl the web through more complex scraping rules might pickup hard to find targets and we can take advantage of that in our web scraper. In other words as the spirit of web-scraping goes: it's smart to take advantage of existing work!
In this article we'll take a look at few common public indexers and how can we use them to discover targets.
First lets overview common pros and cons of this discovery strategy:
Pros:
- Easy: once understood taking advantage of public indexers is surprisingly easy.
- Efficient: public indexes function similar to in-website search bars or often come in easy to parse data dumps that we don't even need connection to discover targets.
Cons:
- Insufficient coverage and stale data: because these are indexes gathered whenever and by whatever there's very little coverage and link quality. For this reason it is best to combine index based discovery with some other discovery techniques.
Using Search Engines
Most common and rich public indexes are search engines like google, bing or duckduckgo - anything that lets humans search the web can be a useful tool for web scraping robots as well.
To see how we would use search engine in web-scraping discover lets take example of https://crunchbase.com. Let's presume that we want to scrape their company overview data
(e.g. https://www.crunchbase.com/organization/linkedin).
In this example we'll use bing.com to query for crunchbase.com urls. Bing is a great tool for web-scrapers as it's easy to scrape (unlike google which employs various anti-scraping strategies) and has relatively good quality results and coverage.
If we take a look at an average Crunchbase company page like https://www.crunchbase.com/organization/linkedin we can determine the url pattern that all company pages follow looks something like: .../organization/<name>
Knowing this we can write domain specific queries in bing.com search box to find other company pages:
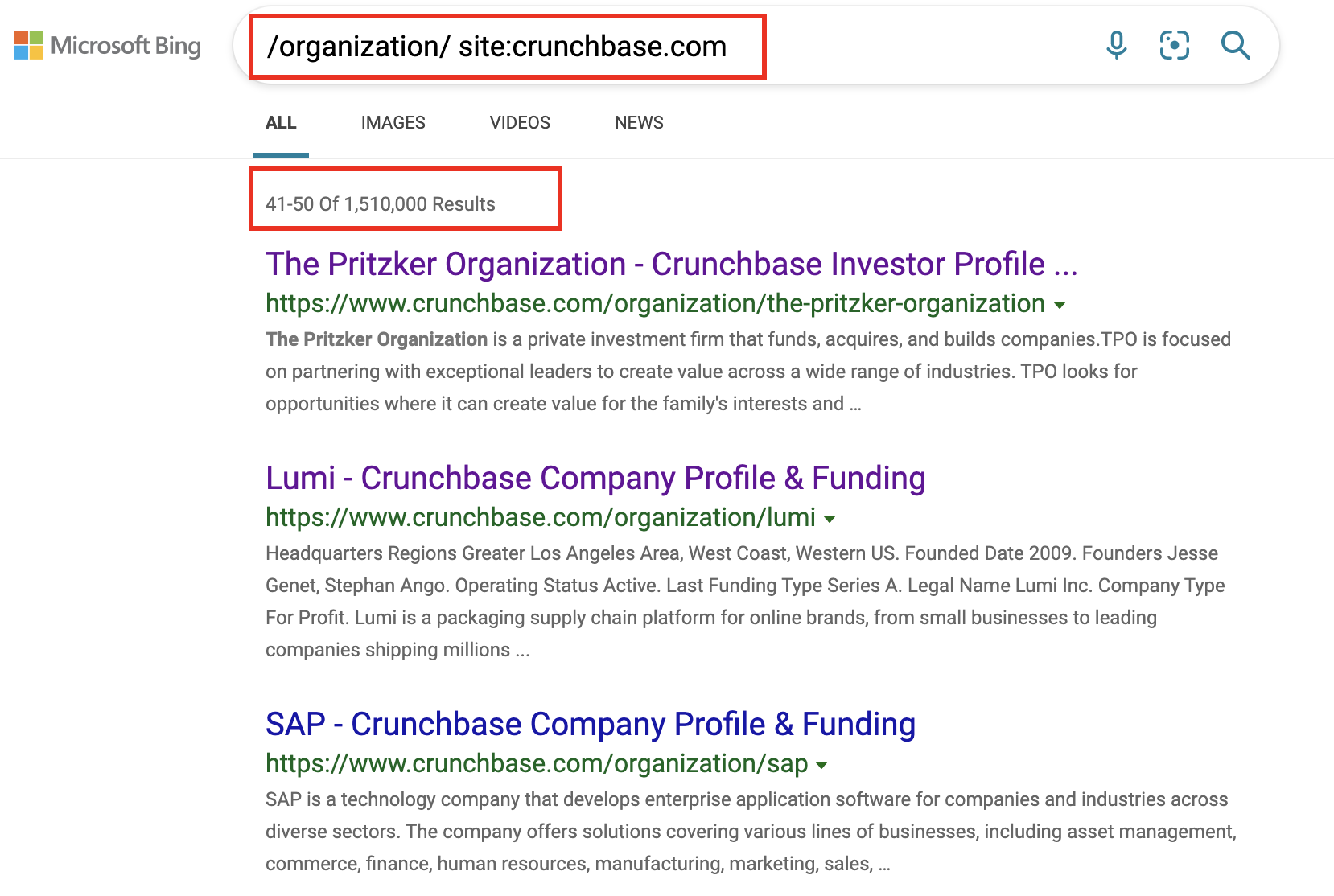
Here we used query /organization/ site:crunchbase.com and bing.com is giving us over a million of results which is pretty close to what the crunchbase is saying they have on their website!
For advanced search keywords/options see bing's advanced search options and bing's advanced search keywords
Other search engines like google, duckduckgo etc. also support similar search syntax. Search can be refined even further with more advanced search rules to find specific scraping targets.
All that being said using search engines to query is not without it's faults.
They are often built for humans rather than robots and have limited pagination (i.e. query will only have 10 pages of results even though it says millions are found) which requires splitting single query into many smaller ones, e.g. searching every letter of the alphabet or particular names. Despite all this discovery approach is surprisingly easy and can often work beautifully for small web scrapers!
Using Public Index Dumps
There are several public web indexes but probably the biggest and most well known one is https://commoncrawl.org/ which crawls the web and provides data dumps publicly for free.
Common Crawl is a nonprofit 501 organization that crawls the web and freely provides its archives and datasets to the public. Common Crawl's web archive consists of petabytes of data collected since 2011. It completes crawls generally every month.
Unfortunately this being an open and free project the crawled htmls are somewhat stale, though as web scraper engineers we can instead use it as an index feed for our own web scrapers.
You can access common crawl's web index here: http://urlsearch.commoncrawl.org/. The data is grouped by months and each month's dataset can be queried on the online playground:
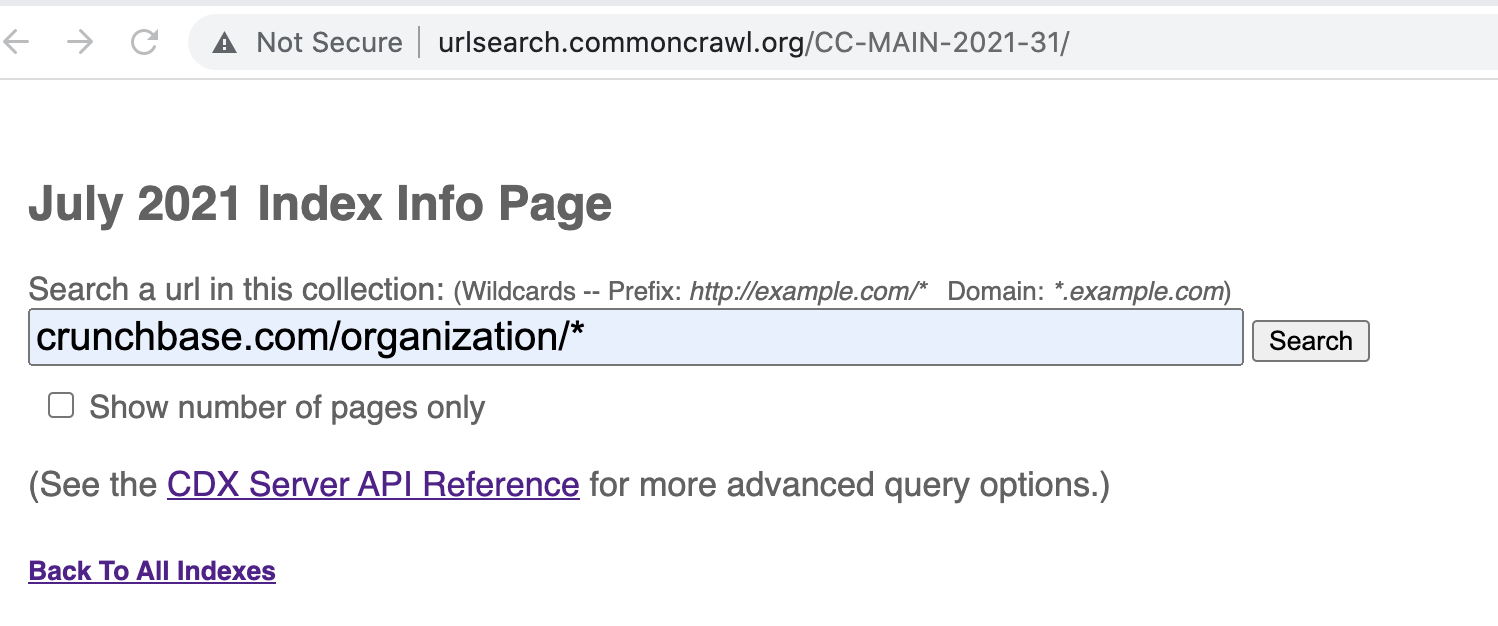
Crawl coverage by commoncrawl highly depends on popularity of the source. Some smaller websites are harder to find while bigger targets can have good data coverage.
Despite coverage issues commoncrawl url dataset is a useful tool to have in web-scraping toolbelt.
If you find Commoncrawl useful it's a non-profit organization accepting public donations!
Using Internet Archive
Another public indexer is archive.org project which aims to archive various internet articles for historic prosperity purposes.
Internet Archive is a non-profit library of millions of free books, movies, software, music, websites, and more.
We can use archive.org website archive as our discovery engine. If we go to https://archive.org and type in our source:
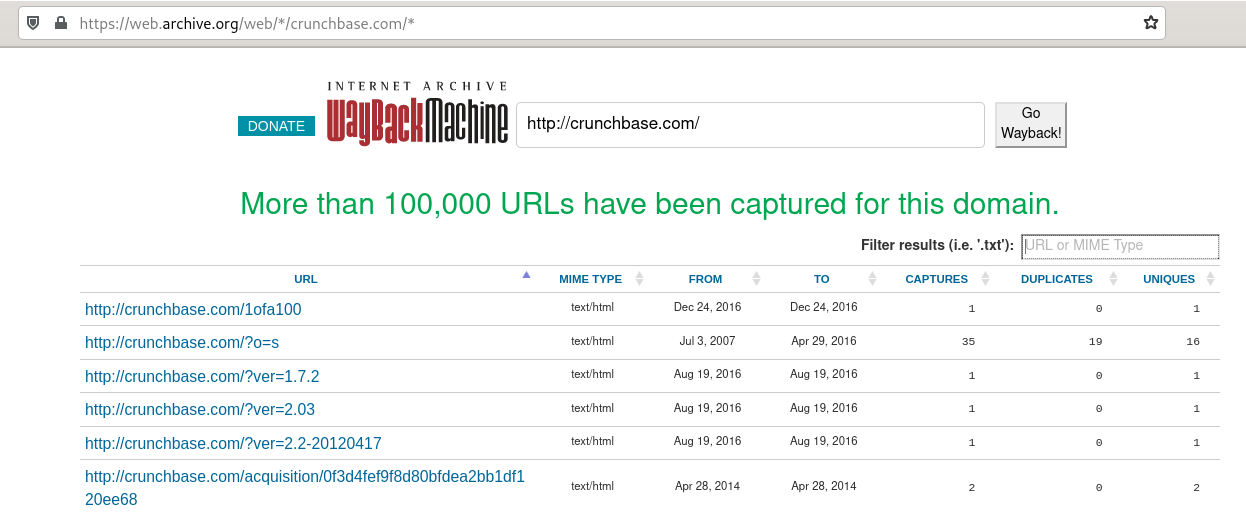
We can see that archive.org has captured a lot of urls! Let's take a quick look how we could scrape it as a discovery source. If we open up web inspector and see requests made when we click search we'll find a backend API url that looks something like this (clickable):
1 2 3 4 5 6 7 8 | |
If we submit get request to this url we'll get the whole dataset of matching results:
1 2 3 4 5 6 7 8 9 10 11 | |
This query generates thousands of unique urls with timestamps of last time they were scraped by internet archive which can be easily adapted as a target discovery source!
If you find Internet Archive useful it's a non-profit organization accepting public donations!
Summary and Further Reading
To summarize using public indexes can be a valid scrape target discovery technique however it comes with a certain level of target quality and coverage uncertainty. It's best used to supplement other discovery techniques or initial prototyping.
Here's a list of several search engines that can be used by web-scrapers for target discovery:
- https://bing.com - great western web coverage, weak anti web-scraping measures.
- https://yahoo.com - uses bing.com database but different algorithms.
- https://www.onesearch.com/ - yahoo's new privacy search engine that is also using bing.com databases but even newer algorithms. Only accessible by US ips.
- https://duckduckgo.com - similar to bing.com but their own dataset.
- https://startpage.com - uses google dataset but easier to access by web-scrapers; see sp project.
- https://yandex.com - great russian web coverage and decent western web coverage.
- https://boardreader.com/ - brilliant forum/discussion board coverage.
For more web-scraping discovery techniques, see #discovery-methods and #discovery for more discovery related subjects.
If you have any questions, come join us on #web-scraping on matrix, check out #web-scraping on stackoverflow or leave a comment below!
As always, you can hire me for web-scraping consultation over at hire page and happy scraping!