
Most web scrapers are made up of two core parts: finding products on the website and actually scraping them. The former is often referred to as "target discovery" step. For example to scrape product data of an e-commerce website we would need to find urls to each individual product and only then we can scrape their data.
Discovering targets to scrape in web scraping is often a challenging and important task. This series of blog posts tagged with #discovery-methods (also see main article) covers common target discovery approaches.
Reverse engineering website's backend API is a common web-scraping technique - why scrape htmls when backend data can be scraped directly? In this article, we'll briefly cover the most common web scraping reverse-engineering subject: the search API.
Using search API for web-scraping
One way to discovery targets in web scraping is to reverse-engineer the search bar for website's search API. It's often one of the best ways to discover targets - let's overview common pros and cons of this approach:
Pros:
- Fresh Targets: search API rarely yields links to outdated targets, as it's exactly what website users see.
- Good Coverage: search API can lead to all the results a website has to offer - if it's not searchable, it's probably not there!
- Efficient: search API result pagination can yield 10-50 results per page and often can be scraped asynchronously.
Cons:
- Domain bound: since every website has their own search structure, the code can rarely be applied to many targets.
- Limited Coverage: some search return limited amount of pages (e.g. there are 900 results but after 10 pages the API does not provide any results) meaning the scraper has to figure out how to get around this limit which can be difficult to implement.
- Slow: Rarely, but some search result pagination cannot be iterated asynchronously. Pages need to be requested one after another, which slows down the scraping process.
As you can see, pros and cons are very mixed and even contradicting - it really depends on website's search implementation. Let's cover a few examples and see what search API discovery is all about.
Example: hm.com
To understand basic search bar reverse-engineering, lets see how a popular clothing website https://hm.com handles its search.
Reversing Search Bar
If we go to the website, open up our web inspector tools and search something, we can see the search requests being made by the browser:
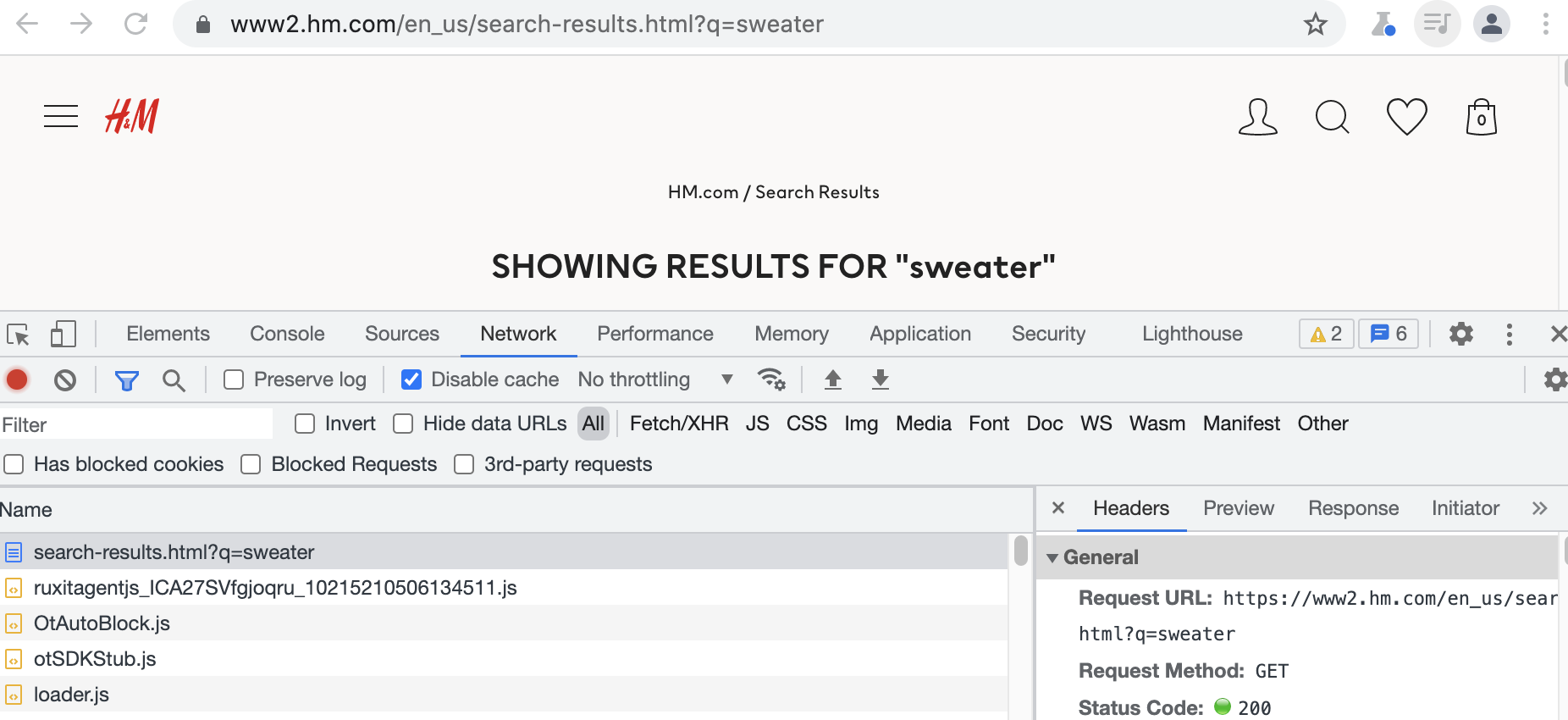
However, this returns us filtered results when we want to discover all products on the website.
For this, we can trick the search API to search empty queries by either searching for an empty string or a space character. In this case no results are returned for an empty string "" but we can force this search by using an url encoded (also called "percent encoded") character for space in the url bar: %20
For more on percent encoding see MDN's documentation.
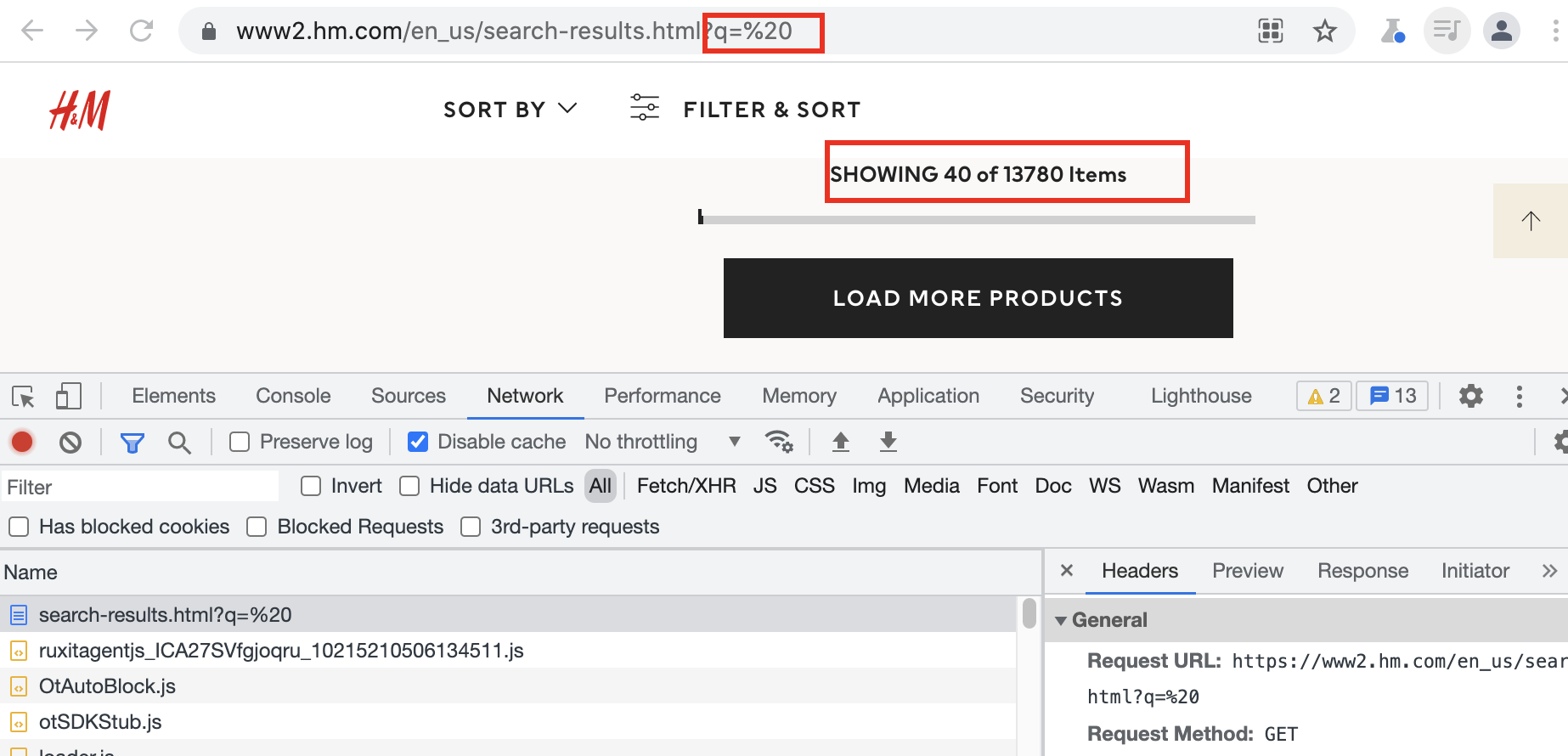
Success! We got 13780 product results!
Now, let's figure out how the search works. If you look at the inspector, no data requests are made, because first page data is embedded into HTML as a javascript variable - this is a common website optimization that we can ignore.
We could scrape HTMLs but we often we don't have to. Modern websites tend to communicate with the backend API in JSON, so let's try to find that.
If we scroll to the bottom of the page and click next page, we can see the actual JSON data request being made for the second page:
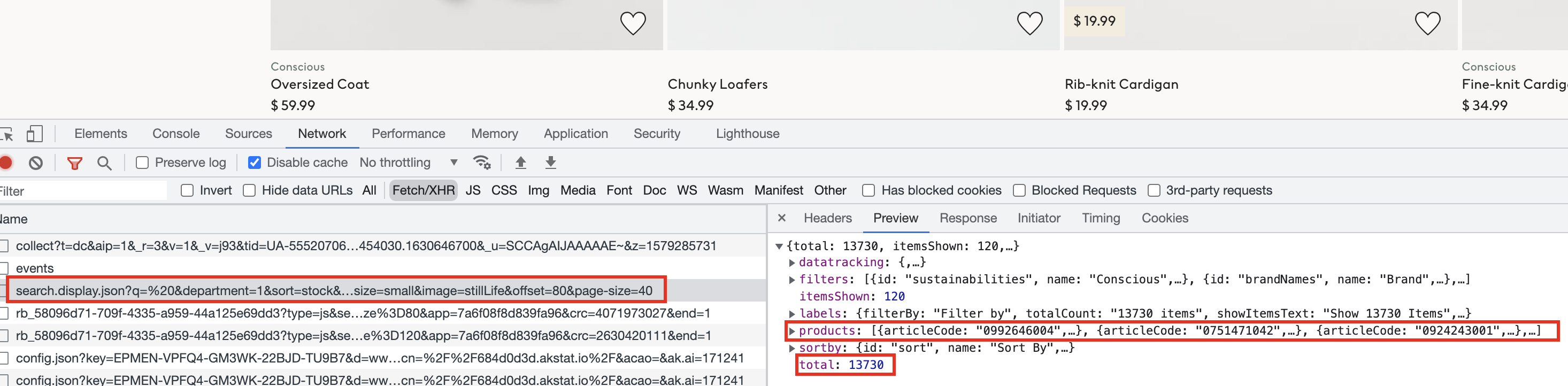
We see a request is being made to backend's search API and it returns us a JSON set of data with product metadata and location. Let's take a look at the request url, so we can replicate it in our scrapper:
1 2 3 4 5 | |
Many modern web APIs are very flexible with parameters - we don't have to use all the junk we see in our web inspector. You can always experiment and see which are necessary and how the content changes when parameters do.
In this example we stripped off a lot of uninteresting parameters and just kept query, offset/limit and sort
This seems like a common offset/limit pagination technique. Which is great for web-scrapers as we can get multiple pages asynchronously - in other words we can request slices 0:100, 100:200, ... concurrently.
Confirming Pagination
Before we can commit to using this API endpoint we should test it for common coverage pitfalls, for example for page limits. Often, search APIs limit the amount of rows/pages a query can request. If we just click the link in the browser:
We can see JSON response and total of results count of 13_730.
Let's see if we can get last page, which at the time of this article would be: offset=13690&page-size=40:
Unfortunately while requests is successful it contains no product data, indicated as empty array: "products": []
It's what we feared and this pagination has a page limit. By messing around with the parameter we can find where the pagination ends exactly and thats at 10_000 results, which is not an uncommon round number.
Let's see a few common ways we could get around this pagination limit:
- Use multiple search queries - common brute force technique is searching many different queries like:
a,b,c... and hope all the products are found. - Apply more filters - this query allows optional filter such as categories. We can collect all categories, e.g.
shoes,dressesetc. and have query for every one of them. - We can reverse sorting - if one query can give us 10_000 results, by reversing sorting we can have 2 queries with 10_000 results each! That's an easy way to double our reach.
For this specific case seems like approach #3 Reversing Sorting is the best approach! As the website only has a bit over 13_000 results and our reach would be 20_000 - this would be a perfect solution.
We can sort our query by price and reach for results from both ends of the query:
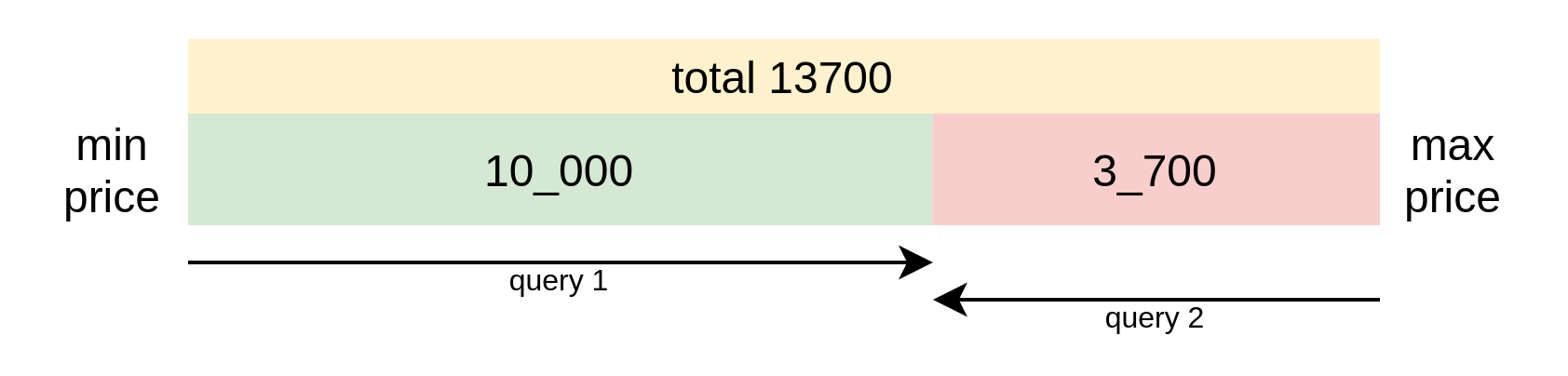
So our first query would get us the first 10_000 cheapest items and the second query would pick up first 3_700 most expensive items. With these two queries, we can fully discover all available products.
Implementation
Having reverse engineering how search API of hm.com works, we can develop our scraping algorithm:
- Get first page to get total result count.
- Schedule request for first
10_000results sorted byascPrice. - Schedule remaining
total - 10_000requests sorted bydescPrice. - Collect responses and parse product data.
Here's quick implementation using Python with asynchronous http client package httpx:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 | |
Here we used asynchronous python and httpx as our http client library to scrape all 13790 products with very few requests just in few minutes!
Summary and Further Reading
To summarize, reverse engineering website's search API is a brilliant scrape target discovery technique, however it's more difficult to develop as it requires reverse-engineer effort and all of the code becomes very domain specific.
For more web-scraping discovery techniques, see #discovery-methods and #discovery for more discovery related subjects.
If you have any questions, come join us on #web-scraping on matrix, check out #web-scraping on stackoverflow or leave a comment below!
As always, you can hire me for web-scraping consultation over at hire page and happy scraping!